
The (Creepy) Reality Of Digitization
by Max von BeustThis is part 4 of my master thesis on Monetization Strategies and Business Models Behind Consumer Data. Find other chapters here:
3. Consumers as Data Models
In order to derive the possible business models that create consumer value through data, a basic understanding of data and its evolution has to be established. The following chapters analyze the state of digital data and describe the path from consumer profiles to consumers as data models, concluding with several techniques for consumer data collection and consumer awareness of data collection.
3.1 Digital Data
Although the concept of 'data' is widely used in everyday conversations, there might be divergent perceptions of what data is, how it is created and how impactful the past years have been in terms of consumer data creation.
3.1.1 Definition
A word that was first used in 1646 is unlikely to have a definition that is purely focused on the usage in digital environments - fittingly, Merriam Webster (2018) provides three different definitions of “data”:
1: factual information (such as measurements or statistics) used as a basis for reasoning, discussion, or calculation
2: information in digital form that can be transmitted or processed
3: information output by a sensing device or organ that includes both useful and irrelevant or redundant information and must be processed to be meaningful
For the current context, the meaning of “data” that was introduced 300 years later (Online Etymology Dictionary,
2018) is of as much relevance as the most recent addition. It is common understanding nowadays that data
is digital, can be transmitted and is a “set of discrete, objective facts about events” (Davenport &
Prusak, 1998, p. 2). When compiled in a meaningful manner, sets of data can amount to information (Tuomi,
1999, pp. 105–107). The latter aspect is essential for understanding the third definition that was provided
above. In a world where sensing devices have become ubiquitous through the “Internet of Things” (IoT)
and these devices measure a wide variety of data points, redundancy and irrelevance occur frequently.
In short, data is the smallest digital representation of reality.
For better understanding, the term “big data” has to be mentioned - this concept is not a new kind or
definition of data, but draws a line between “traditional” data and the emergence of data in larger amounts
(volume), more variety and at a higher speed (velocity) than previously imaginable. A good analysis of
different definitions of “big data” can be found at Gandomi and Haider (2015, pp. 137–139). Crucially,
they also point out that the term “big data” is not absolute, but relative - what is “big data” today
will be “traditional data” tomorrow.
the term “big data” is not absolute, but relative - what is “big data” today will be “traditional data” tomorrow
3.1.2 Data Sources
A brief analysis of different data sources and data generation as the first step in the data value chain
is helpful to understand the concepts that will be discussed in the following chapters (Miller & Mork,
2013, p. 58). Authors differentiate between external (i.e. supplemental data) and internal (i.e. enterprise-level)
data (Botta, Digiacomo & Mole, 2017; Sorescu, 2017, p. 694).
External data is open to the public e.g. databases of governments or institutions, social media data,
wikis, and so forth. Internal data is data that is generated inside an organization, such as data about
employees, the business, the market, but also data that is collected by the organization outside of organizational
boundaries, such as consumer data. Although internal data sources like data from production facilities
have increased manifold (Lee, Bagheri & Kao, 2015, pp. 18–19), data that is generated by consumer-sensor-,
or more generally, consumer-machine-interaction is the most relevant for the current thesis as it focuses
on data about individuals.
Finding a concise high-level overview of different data sources is a major challenge when looking at
academic literature, even though authors refer to “data sources” in their works (Cuzzocrea, Song & Davis,
2011, p. 102; Erevelles et al., 2016, pp. 898–901). Chen, Chiang and Storey (2012, pp. 1167–1182) list
a large variety of data sources, but the most comprehensive aggregation and overview of (big) data sources
can be found at van Rijmeam (2013) as shown in Table 1.
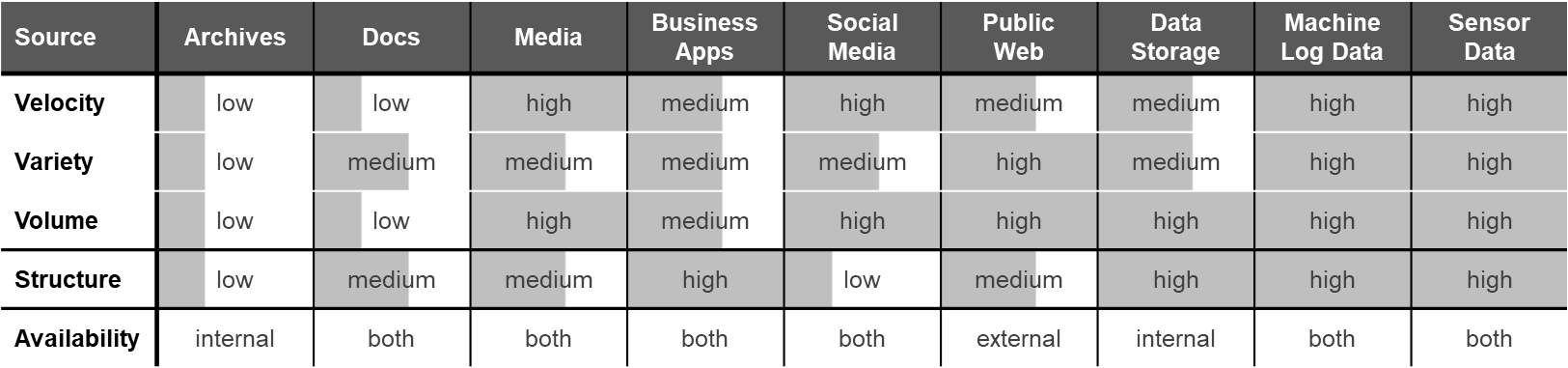
An additional breakdown was developed in the United Nations Economic Commission for Europe (USECE) Statistics
Wiki (Vale, 2013) and is discussed by the International Monetary Fund (IMF) (Hammer, Kostroch & Quiros,
2017, pp. 35–40). Here, the main classifications are social networks (human-sourced information), traditional
business systems (process-mediated data) and IoT (machine-generated data). Unfortunately, this concept
has only been proposed, but is neither further pursued nor backed up by research, although the overarching
idea and the currently defined subcategories exceed current literature.
As to the availability of the specified data sources, Table 1 shows that the previously made distinction
between internal and external is not precise - most data sources have both internal and external availability.
Applying the criteria for big data, social media, the public web, machine log data and sensor data can
be defined as “big”.
Overall, it can be seen that companies have a wide variety of different data sources at their disposal
and most of these sources can include information about private consumers.
3.1.3 Data Evolution
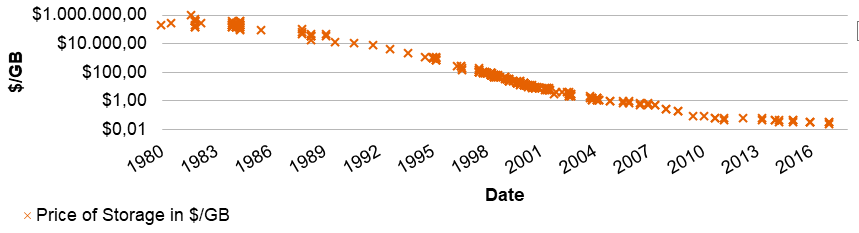
The multitude of data sources has evolved rapidly over the last years. Although archives have been around for a long time, the public web only started growing in the 1990s and machine log data or sensor information are as recent developments as social media are. As the generation of data has a direct impact on the amount of storage needed, the price of a storage unit is a good starting point when describing the evolution of data.
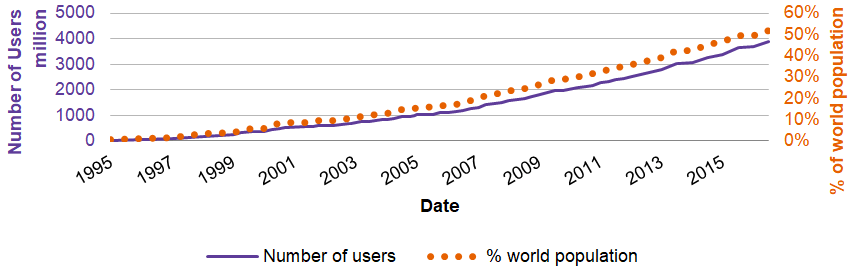
1995 only 0.4% of the world population was using the web, whereas more than 50% were actively connected to the internet in 2017
Here, Komorowski (2014) provides data from 1980 to 2014, when it is continued by Klein (2017). It is evident that prices for one gigabyte (GB) of data storage have decreased rapidly in the past 20 years as shown in Graph 1 (note the logarithmic scale on the y-axis), even though supply has not been able to match demand (Rizzatti, 2016) at a development pace that has exceeded the speed of Moore’s Law (Mearian, 2017).
At the same time, we can see a rapid adoption of internet technologies - in 1995 only 0.4% of the world population was using the web, whereas more than 50% were actively connected to the internet in 2017. The absolute numbers are even more impressive with just 16 million active users in 1995 compared to 3.8 billion only 22 years later. Graph 2 gives an overview of the rapid growth in absolute and relative figures. (Internet World Stats, 2017)
These developments are reflected in the total amount of internet traffic globally, as reported by Cisco (2017b,
p. 5): In 1992, overall internet traffic was 100GB per day, increasing to 100GB per second within only
10 years and after that increased by a staggering 26,600% by 2016. When looking at these numbers on a
per capita basis, this means <1GB monthly traffic in 2007 compared to 10GB in 2016.
Lee (2017, pp. 296–298) breaks these rapid developments down into three different phases of rapid expansion
(“Big Data 1.0”, “Big Data 2.0”, “Big Data 3.0”) in the data evolution. The first phase is characterized
by the public adoption of internet technologies and the arrival of e-commerce (1994). Businesses were
the major content contributors and data analysis focused on text-based technologies. Though data was
still fairly easy to grasp and the quality of individual data points was high, the aggregation of data
was not able to accurately predict reality in those times.
The subsequent advent of social media platforms and an increase in UGC initiated the second phase in
2005. Terms such as “Web 2.0” and more sophisticated data analysis are core characteristics of that era.
Companies not only are able to refine their CRM, gain insights into consumer behavior and process images
and speech with machine learning (ML) but also establish online monetization models (as described in
chapter 2.4 on p.10). These more advanced methods of data handling are needed because an increase in
quantity of data is accompanied by a decrease of quality of the individual data point. This can be explained
by the introduction of new data sources and a decrease of storage cost which has led to the accumulation
of unfiltered data with often erroneous and useless data points - on this basis, veracity was proposed
as an additional challenge of big data (Gandomi & Haider, 2015, p. 139). Nevertheless, this development
leads to an increase of the information quality of aggregated data due to better data handling according
to Lee (2017, pp. 296–298).
The current era, which started in 2015, is not dominated by consumer-generated data but the creation of data about consumers, processes and machines through IoT
The current era, which started in 2015, is not dominated by consumer-generated data but the creation of data about consumers,
processes and machines through IoT. Further improvements in data processing and analytics will allow
for real-time insights and a quantitative and qualitative increase of data from sensors will enable the
virtualization of the world. This implies the possibility of creating a virtual representation or digital
twin of reality.
The current phase of the data evolution is likely to continue - or even increase in speed - following
the predictions of Cisco, expecting a 24% CAGR in consumer internet protocol (IP) traffic from 2016 to
2020 (Cisco, 2017a, p. 6). Mobile data is expected to increase at a 47% CAGR to 41.417 PB (petabyte )
of data. Global annual IP traffic is expected to reach 3.3 ZB (zetabyte ) per year by 2021 (Cisco, 2017b,
p. 2).
This implies the possibility of creating a virtual representation or digital twin of reality
This information and the rapid growth that is reflected in decreasing storage cost, increasing internet adoption and expanding data generation makes it evident that the digitization of the world leads to more data about everything around us. Currently, it seems to be evident that the evolution that started in the 1950s will not stop any time soon. We have moved from an era of raw and institutional data to smart data, and then from data about identities to people data that enable companies to interact with consumers on a more personal basis (Maycotte, 2014).
3.2 Consumer Profile vs. Consumer Data Model
One of the most essential components of modern-day marketing is accurate information about customers and consumers. This
information usually is stored in consumer profiles, which are dealt with in the recommendation and privacy
literature. These profiles can be created in numerous different ways, but the optimum differentiation
of techniques is to look at the dimensions of implicit and explicit profiles (Fan, Gordon & Pathak, 2005,
p. 214).
Explicit information is provided by the user directly with high awareness and involvement, whereas implicit
data is collected about the consumer through feedback or behavior tracking (Ellingwood, 2017). Thereby,
customer profiles are created with online actions and metrics such as clicks, purchases, add-to-cart
and their frequency, history and development (Park & Chang, 2009, pp. 1933–1934) which can be enriched
by offline information about transactions or sales preferences. In order to improve the accuracy of these
profiles, businesses can group consumers and gain additional insights into consumer behavior. Nonetheless,
consumer profiles mainly include accurate explicit information such as name, age, sign-up dates and nationality
that are enhanced through online behavioral data on preferences - all this data is collected through
online behavior of a consumer.
Nowadays, we are moving on from consumer profiles to a world where we are able to model a consumer in
the virtual world. The basic idea is that the collection of data moves from the virtual/ online world
to real/ offline environments - this differentiation is the second dimension of the creation of consumer
comprehension. The increasing scope of data enables the step from customer profiles, which created an
understanding of consumer behavior, to the world of consumers as data models which create the ability
to predict consumer behavior.
Nowadays, we are moving on from consumer profiles to a world where we are able to model a consumer in the virtual world
Here, implicit information about consumers might not be as accurate when looking at the single data point, but the amount of information and knowledge that can be extrapolated from a large amount of this data exceeds traditional methods by far. Although the line is blurred here, the collection of data about real-world interactions of consumers can still be split into explicit and implicit data. This difference is best described with examples.
Example 1: Fitbit
A consumer wearing a health tracking device such as a Fitbit has the (initial) awareness of the process
of data collection; nonetheless, the data provided allows a fairly accurate understanding and predictability
of this individual. Data generated by this tracking device can fall into low and high awareness at the
same time - a consumer can be aware of certain aspects of tracking (e.g. self-reported data), but less
so about others (e.g. digital exhaust or profiling data) (Morey, Forbath & Schoop, 2015, p. 102).
Example 2: Self-Driving Vehicles
In the case of a consumer using a self-driving vehicle in a public environment, the process of data
generation and collection is less explicit. Information about driving style (in cases of a human driver
intervening), routing and possibly even medical conditions can be collected (Strickland, 2017). At the
same time, public agencies might collect data through visual tools such as cameras or location information
through GPS (Vincent, 2018a). This generation or collection of data occurs (mostly) without the consumer
consenting to or being aware of it (Schneier, 2015).
An additional differentiating factor of consumer profiles and consumers as data models is that the subject
has a lower to no understanding of the implications of data collection. While consumers are aware of
certain e.g. marketing-related implications of their profiles (Morey et al., 2015, p. 103), the awareness
of possible consequences of environmental- and body-related data is low.
We, the subjects, have a low to no understanding of the implications of data collection
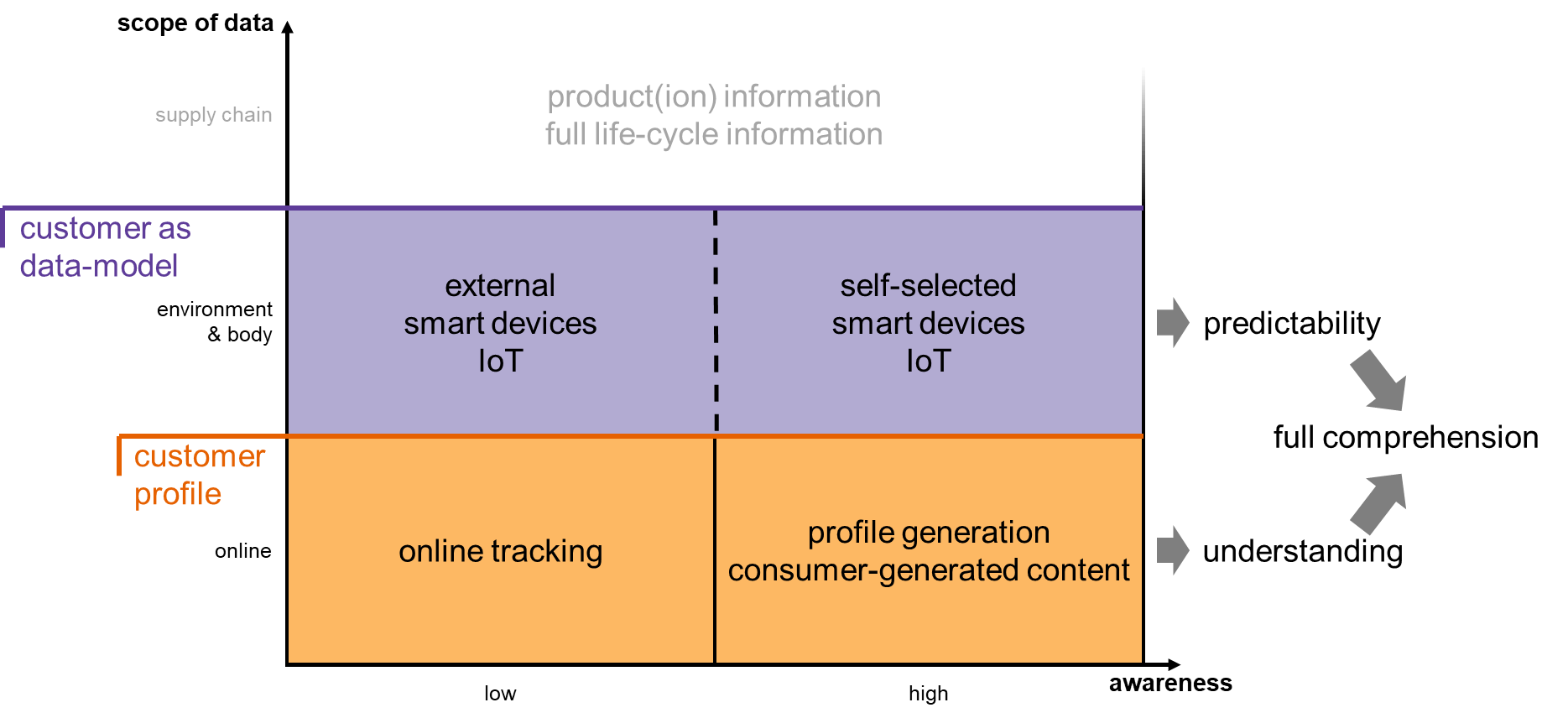
Figure 6 depicts the positioning of consumer profiles and consumers as data models along the dimensions of consumer awareness of data collection and the scope of data collection. As noted previously, profiles are created through consumer interactions online, whereas the consumer as a data model expands into consumer-technology interactions in the physical environment (including future consumer-technology interactions within the body of the consumer). Information that is generated or collected without direct consumer interaction (such as production data about products consumers buy or waste they produce) are not included in this consumer data model.
Continue with: